本帖最后由 automation 于 2013-7-28 11:43 编辑
这次很厚道,titan没砍双精度 但是780的双精度大幅砍了:
http://www.expreview.com/25733.html

3494/190=18.3895 看来是1/18 啊
看来titan不是平白贵那么多的
titan只略微阉了hyper-Q。
用workflow可以实现grid级别的并行。而hyper-Q增加了硬件队列,可以让多个cpu线程控制多个workflow同时执行。
K20上是全规格的,内部可以同时有32个队列,也就是可以支持32个cpu线程的grid同时执行。
这样轻载任务通过CPU的MPI或者openMP 也可以让GPU充分满载。
超算上用E5的双路节点正好32线程,MPI状态下大家都可以用GPU了。
titan大概阉到8条队列吧。也就是说如果32个线程都递交了任务,最多只能同时执行8个,其他grid要等待。
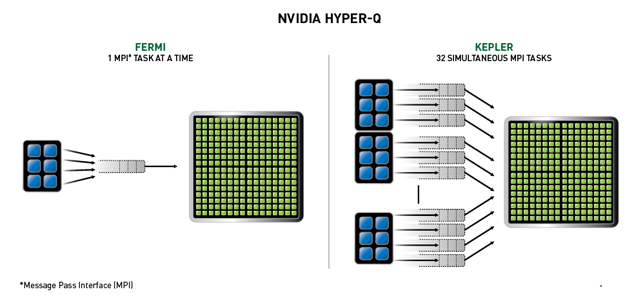
fermi时代并行度很低:

compute capability 3.5 的 hper-Q:

在CUDA SDK 5.0中也有一个关于Hyper-Q的简单实例,启动32个并行stream,预计如果这32个stream串行执行,需要0.640秒,如果并行执行,理论上需要的时间只有1/32也就是0.020秒,但实际上执行了0.053秒。当然了理想状态和实际还是有一定差距的,但这也足以体现出并行执行的速度优势了。

| 

 发表于 2013-7-28 08:18:37
发表于 2013-7-28 08:18:37
 发表于 2013-7-28 08:23:22
发表于 2013-7-28 08:23:22



 。
。